火车采集器zblog(火车采集器教程视频)

火车头采集器无法使用的解决方法
1、因为您系统开启了自动更新功能导致.net framework版本不对。请升级过.net框架的会员下载本贴附件MaxToCode.dll 直接覆盖到火车采集器程序根目录,替换原文件即可,此文件适用于免费及商业版本。
2、用右键单击火车头图标,然后选择“以管理员身份运行”,就可以正常打开了。
3、卸载它。如果更新下载补丁不是该软件的错误补丁,也会引起软件异常,解决办法:卸载该软件,重新下载重新安装试试。顺便检查开机启动项,把没必要启动的启动项禁止开机启动。
4、跟电脑的系统有关。下面是火车头采集器V9在windows10下无法运行/没反应解决方案:先进入到WI1N10的查看更新历史记录的页面(ctrl+x,选择搜索输入查看更新历史记录)。然后单击显示的卸载更新按钮,进入到已安装更新界面。
")
火车采集器爬取出来的数据不变化的原因
1、原始网页格式问题:如果原始网页的文章格式不包含换行符,那么火车头采集器抓取到的文章自然也就没有换行。这可能是因为原始网页使用了特殊的HTML标记语言或者CSS样式,导致换行符被忽略或者隐藏。
2、火车头采集器采集的内容网站后台显示是因为他已经联网传输了,但如果说前段页面没有显示的话,应该是仪器设置的问题。
3、可能是因为您系统开启了自动更新功能导致.net framework版本不对可能是因为您系统开启了自动更新功能导致.net framework版本不对。
4、采集的时候,最好先把排序ID定义好,这样就不存在乱序问题,如果系统构架没有排序ID这个东西,那就设置单线程发布。
5、想办法让你的标签抓取内容不为空,比如你可以把抓取内容的规则设置大一点,就算这个标签为空,不要设置标签的代码过滤,应该可以抓些代码,让这个标签内容不为空,那么采集器就会正确匹配了。
火车头采-集器,做内容采集规则,涉及到一个标签的数据处理?
具体步骤如下: 打开八爪鱼采集器,并创建一个新的采集任务。 在任务设置中,输入要采集的网址作为采集的起始网址。 配置采集规则。可以使用智能识别功能,让八爪鱼自动识别页面的数据结构,或者手动设置采集规则。
完成好上面一步后,我们就进行下一步,多级网址获取规则 到了这一步网址的选择已经做好了,下面就是内容的标签修改了,意思就是采你想要采集的内容。
第一步采集网址,下载好火车头采集器后打开,新建一个任务,任务名随意。把需要采集的网站文章列表页网址添加到起始网址。从图中看出该列表页有34页,每页有N篇文章。
火车头采集器本地编辑任务采集数据功能的图文使用教程
首先在在线下载频道下载该软件 安装下载好的安装文件 等待安装完毕 打开后进入主火车头主页面 然后点击任务小三角,新建一个新的任务,新建好任务后,将进入任务主页面,填写好任务名。
方法/步骤将火车头采集器及WordPress网站安装好,并下载1818乐淘淘提供的wordpress2web免登陆在线发布模块。
安装并运行“火车头采集器”程序,在弹出的登陆界面中直接点击“登陆”按钮就可以以免费版身份登陆。请点击输入图片描述 3 在程序主界面中,点击“新建”下拉箭头,从中选择“任务”项。
火车头采集器中网盘上传功能的使用方法
1、安装并运行“火车头采集器”程序,在弹出的登陆界面中直接点击“登陆”按钮就可以以免费版身份登陆。请点击输入图片描述 3 在程序主界面中,点击“新建”下拉箭头,从中选择“任务”项。
2、首先在在线下载频道下载该软件 安装下载好的安装文件 等待安装完毕 打开后进入主火车头主页面 然后点击任务小三角,新建一个新的任务,新建好任务后,将进入任务主页面,填写好任务名。
3、采集到的内容保存到了数据库里,按上图操作即可找到这个数据库,打开之后导出发布随便你了。
4、火车头采集器通常通过网址抓取网站返回的源代码,然后在源代码中提取需要的信息。因此,采集数据需要先采集网址,然后再采集数据。
5、火车头采集器采集信息分两个步骤:1,采网址。这一步也是就告诉软件,有多少个网页需要去采,并给出具体的网页地址。2,采内容。有了网址之后,就可以去这个网址上采集信息了,但网页上信息众多,软件不知道你想采哪些。
6、方法/步骤将火车头采集器及WordPress网站安装好,并下载1818乐淘淘提供的wordpress2web免登陆在线发布模块。
本文由admin于2024-01-06发表在靑年PHP官网,如有疑问,请联系我们。
本文链接:https://www.qnphp.com/post/264973.html
相关文章
-

视频营销案例,视频营销案例分析报告模式
-
短视频矩阵seo系统源码,短视频矩阵化运营策略
-
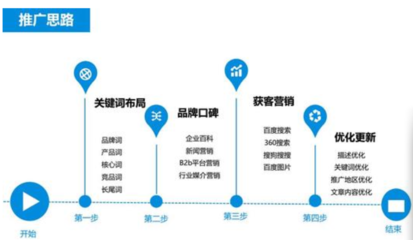
seo推广思路,seo推广教程视频
-

短视频seo询盘获客系统,短视频seo询盘获客源码
-

免费b站推广视频,免费b站推广视频怎么赚钱
-
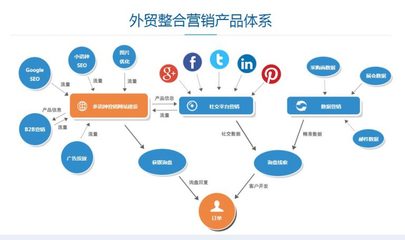
如何推广一个网站,如何推广一个网站的视频
-
论坛seo教程,论坛ui
-

b站视频推广网站,b站推广是什么


")
")
")




